Cartesia (cartesia.ai) is a real-time speech synthesis platform engineered for latency-critical applications. Where most TTS APIs are optimized for batch audio generation, Cartesia is purpose-built for conversational AI — phone agents, voice assistants, and real-time interactive experiences where the gap between the LLM finishing a sentence and the user hearing it must be measured in milliseconds, not seconds.
How Cartesia Works
Cartesia's Sonic model uses a state space architecture (rather than transformer-based diffusion) to deliver streaming audio output with end-to-end latency under 80ms. You send text to the API — either full sentences or streaming token-by-token as the LLM generates them — and receive a PCM or Opus audio stream back in real time. The API integrates directly into voice agent stacks, typically paired with a speech recognition provider like Deepgram on the input side to complete a full duplex voice pipeline.
Key Features
- Sub-80ms synthesis latency — purpose-built for real-time voice agent deployment
- Streaming token input — accepts LLM token streams directly, eliminating sentence-completion wait time
- Voice cloning — create custom voices from short audio samples for branded agent personas
- Emotion and style control — adjust speaking pace, tone, and expressiveness via API parameters
- Multi-language support — English-first with expanding language coverage
- Pairs with Deepgram ASR — commonly integrated alongside Deepgram for a complete speech-in / speech-out pipeline
Cartesia Pricing
Source: cartesia.ai/pricing, verified March 2026.
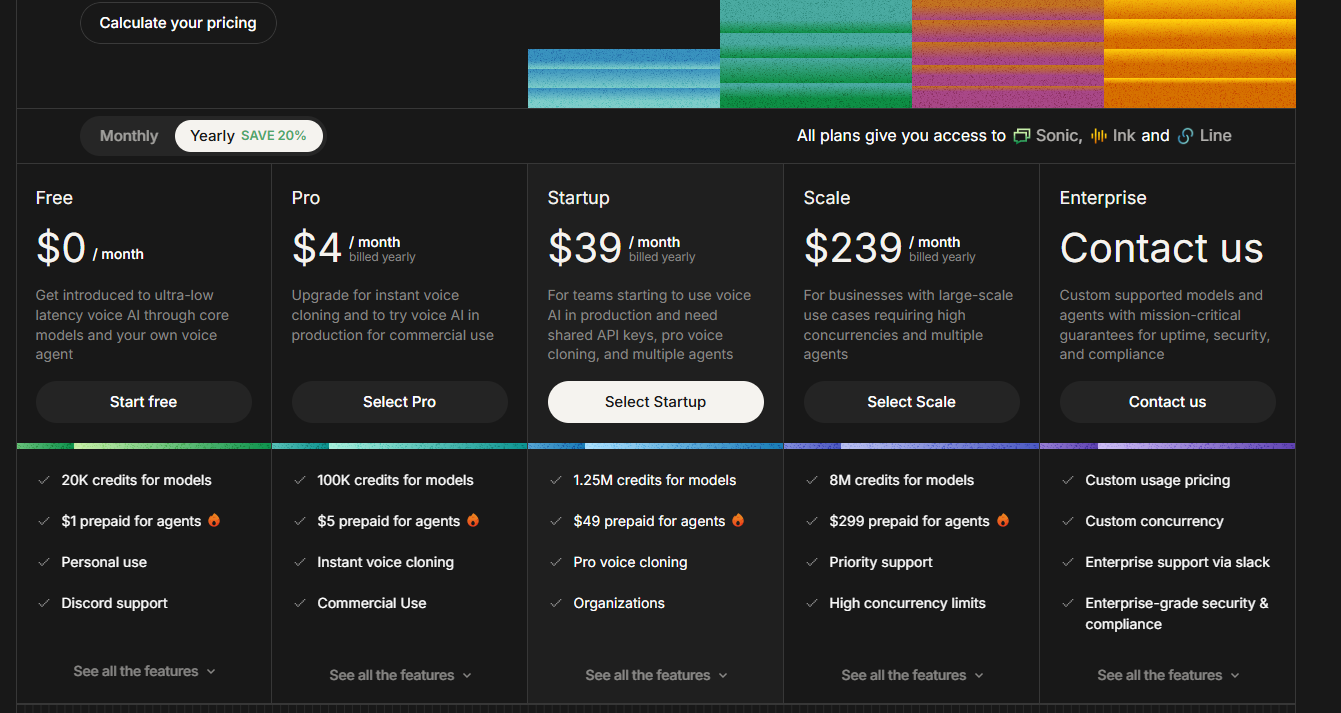
- Free — $0/month — Limited character quota for testing and evaluation.
- Starter — $4/month — Modest character allowance for small projects and side builds.
- Pro — $39/month — Higher quota, voice cloning access, and priority API throughput.
- Scale — $239/month — High-volume production quota with dedicated support and SLA commitments.
Who Should Use Cartesia?
Cartesia is the right TTS layer for developers building real-time voice agents — whether on Retell AI, Vapi, LiveKit, or a custom WebRTC stack. If your use case involves a phone agent or interactive voice assistant where latency determines whether the conversation feels natural or robotic, Cartesia's sub-80ms pipeline is the current state of the art. It is typically combined with Deepgram for speech recognition to form a complete real-time voice pipeline without writing low-level audio infrastructure.